[Spring] Maven이란? 빌드툴
Maven이란?
자바 프로젝트의 빌드(build)를 자동화해주는 빌드 툴(build tool)이다. 즉, 자바 소스를 compile하고 package해서 deploy하는 일을 자동화해주는 것이다.
Maven이 참조하는 설정 파일
1) settings.xml
maven tool 자체에 관련된 설정을 담당한다.
MAVEN_HOME/conf/ 아래에 있다.
2) pom.xml
하나의 자바 프로젝트에 빌드 툴로 maven을 선택했다면, 프로젝트 최상위 디렉토리에 pom.xml 파일이 생성된다.
pom.xml은 POM(Project Objet Model)을 설정하는 부분으로 프로젝트 내 빌드 옵션을 설정하는 부분이다.
꼭 pom.xml이라는 이름을 가진 파일이 아니라 다른 파일로 설정할 수 있지만 권장하진 않는다. (mvn -f ooo.xml test)
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>demo</name>
<description>Demo project for Spring Boot</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.5.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>1. 프로젝트 정보
- <modelVersion> 4.0.0이라고 써있는 것은 maven의 pom.xml의 모델 버전이다. 형식이 4.0.0 버전이라고 이해하면 된다.
- <groupId> 프로젝트를 생성한 조직 또는 그룹명으로 보통, URL의 역순으로 지정한다.
- <artifactId> 프로젝트에서 생성되는 기본 아티팩트의 고유 이름이다. maven에 의해 생성되는 일반적인 artifact는 <artifact>-<version>.<extension> (예) demo-0.0.1-SNAPSHOT.jar
- <version> 어플리케이션의 버전. SNAPSHOT이 붙으면 아직 개발 단계라는 의미이다.
- <packaging> jar, war, war, pom 등 패키지 유형을 나타낸다.
- <name> 프로젝트명
- <description> 프로젝트 설명
- <url> 프로젝트를 찾을 수 있는 url
- <properties> pom.xml에서 중복해서 사용되는 설정(상수) 값들을 지정해놓는 부분. 다른 위치에서 ${...}로 표기해서 사용할 수 있다. (java.version에 1.8을 적용하고 다른 위치에서 ${java.version}이라고 쓰면 "1.8"이라고 쓴 것과 같다.
2. 의존성 라이브러리 정보
최소한 groupId, artifactId, version 정보가 필요하다.
스프링 부트의 spring-boot-starter-* 같은 경우 부모 pom.xml에 이미 버전 정보가 있어서 version을 지정할 필요가 없다.
3. 빌드 정보
build tool: maven의 핵심인 빌드와 관련된 정보를 설정할 수 있는 곳이다.
maven에는 라이프 사이클이 존재한다. default, clean, site 라이프 사이클로 나누고 세부적으로 phase(페이즈)가 있다.
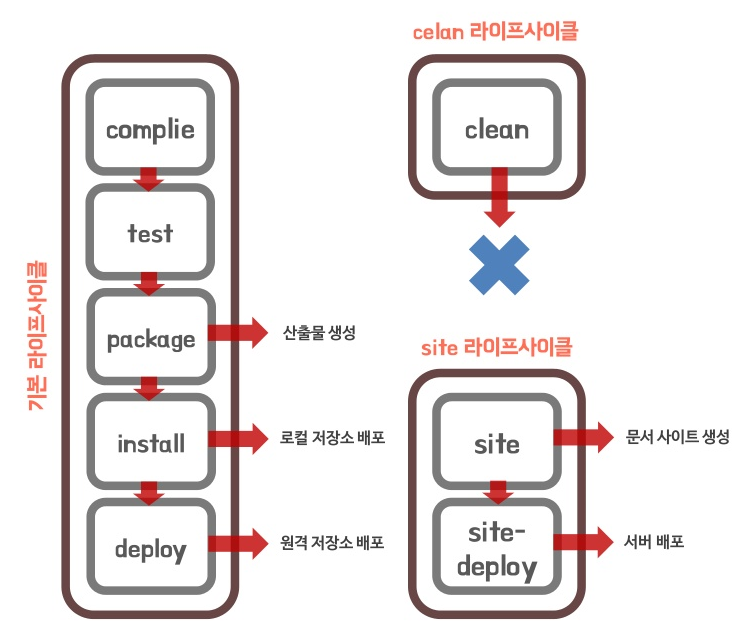
maven의 모든 기능은 plugin(플러그인)을 기반으로 동작한다. 플러그인에서 실행할 수 있는 각각의 작업을 goal(골)이라 하고 하나의 페이즈는 하나의 골과 연결되며, 하나의 플러그인에는 여러 개의 골이 있을 수 있다.
Life-Cycle
- mvn process-resource: resources:resources의 실행으로 resource 디렉토리에 있는 내용을 target/classes로 복사한다.
- mvn compile: compiler:compile의 실행으로 src/java 밑의 모든 자바 소스를 컴파일해서 target/classes로 복사
- mvn process-testResources, mvn test-compile: test/java의 내용을 target/test-classes로 복사 (참고로 test만 mvn test 명령을 내리면 라이프 사이클상 원본 소스로 컴파일된다.)
- mvn test: surefire:test의 실행으로 target/test-classes에 있는 테스트케이스의 단위 테스트를 진행한다. 결과를 target/surefire-reports에 생성한다.
- mvn package: target 디렉터리 하위에 jar, war, ear 등 패키지 파일을 생성하고 이름은 <build>의 <finalName>의 값을 사용한다. 지정되지 않았을 때는 <artifactId>-<version>.<extension> 이름으로 생성한다.
- mvn install: 로컬 저장소로 배포
- mvn deploy: 원격 저장소로 배포
- mvn clean: 빌드 과정에서 생긴 target 디렉터리 내용 삭제
- mvn site: target/site에 문서 사이트 생성
- mvn site-deploy: 문서 사이트를 서버로 배포
위와 같은 진행 순서로 라이프 사이클이 진행된다.
<build>에서 설정할 수 있는 값을 확인해보자.
- <finalName>: 빌드 결과물(ex .jar) 이름 설정
- <resources>: 리소스(각종 설정 파일)의 위치를 지정할 수 있다. <resource> 없으면 기본으로 src/main/resources
- <testResources>: 테스트 리소스의 위치를 지정할 수 있다. <testResource> 없으면 기본으로 src/test/resources
- <Repositories>: 빌드할 때 접근할 저장소의 위치를 지정할 수 있다. 기본적으로 메이븐 중앙 저장소인 http://repo1.maven.org/maven2로 지정되어있다.
- <outputDirectory> : 컴파일한 결과물 위치 값 지정, 기본 target/classes
- <testOutputDirectory> : 테스트 소스를 컴파일한 결과물 위치 값 지정, 기본 target/test-classes
- <plugin> : 어떠한 액션 하나를 담당하는 것으로 가장 중요하지만 들어가는 옵션은 제 각각이다. 다행인 것은 플러그인 형식에 대한 것은 안내가 나와있으니 그것을 참고해서 작성하면 된다. <executions> : 플러그인 goal과 관련된 실행에 대한 설정 / <configuration> : 플러그인에서 필요한 설정 값 지정
출처
https://jeong-pro.tistory.com/168
'web > Spring' 카테고리의 다른 글
| [Spring] HandlerInterceptor를 활용하여 컨트롤러 중복코드 제거하기 (0) | 2022.06.15 |
|---|---|
| [Spring] Builder 기반으로 객체를 안전하게 생성하는 방법 (0) | 2022.06.03 |
| [Spring JPA] Dirty Checking(더티체킹)이란? (0) | 2022.05.26 |
| [Spring JPA] @Modifying 어노테이션 (1) | 2022.05.25 |
| [Spring JPA] JPQL DELETE ENTITY with JOINs using JPA / SQL DELETE with join condition (0) | 2022.05.24 |

댓글 개