위 서술형 예상문제 보고 프린트한 거고 보충할 부분, 제가 모르는 부분, 헷갈리는 부분, 중요하다고 생각되는 부분도 필기해놓았어요! 참고하셨으면 좋겠습니다. 수제비 카페에서 주는 데일리 문제가 꽤 좋으니 풀어보시길 추천합니다. 저는 시험 3일 전에 알아서 몰아서 풀면서 외웠습니다.
참고로 파이썬 문제도 나왔었는데 제가 알기론 실기에 나오는 언어가 java, c, python으로 알고 있습니다.(확실하지 않음) 저는 파이썬은 배운 적이 없어 몰랐고 주언어가 자바랑 씨 언어라, 설마 파이썬이 나오겠어? 싶었는데 나와서 당황했습니다. 결국 한 문제를 날렸습니다. 아쉬웠는데 그래도 합격해서 다행이네요... 지금 실기 준비하시는 분들은 언어공부도 꼼꼼히 하시길!!
그리고 서술형 문제 자체는 논란이 없도록 최대한 후하게 채점해주는 느낌이 들었습니다.
중요 포인트만 들어가면 맞게 해 주시는 것 같았습니다.
대신 단답형 같은 경우는 철자가 틀리기만 해도 감점이었던 것 같아요. 단답형인 경우 영어로 작성하는 문제도 있었던 것으로 기억하니 꼼꼼히 외우는 것을 추천드려요.
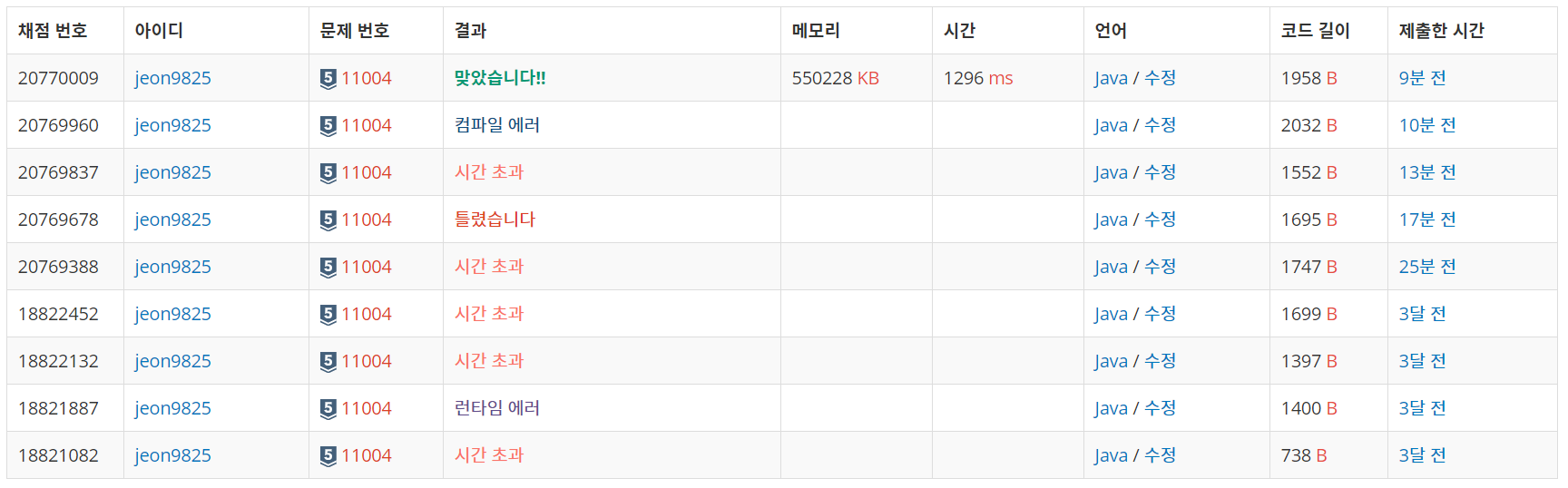
백준 11004번 문제부터 얘기하자면 어렵지 않은 난이도인데 시간 초과로 계속 풀지못했던 문제
일단 학교에서 배운 quick sort와 quick select에 대해서 설명해보고자 한다.
1. quick sort (퀵 정렬)
1) 배열 나누기
임의의 값을 기준으로, 기준 값보다 작은 값들은 배열의 앞부분으로 이동하고, 기준 값보다 큰 값들은 배열의 뒷부분으로 이동하는 알고리즘.
기준 값: 입력 배열의 끝 값 (혹은 중간 값)
1구역: 기준 값보다 작거나 같은 값들이 위치할 곳
2구역: 기준 값보다 큰 값들이 위치할 곳
3구역: 아직 비교하지 않아서 위치가 정해지지 않은 값들
2) partition 구현
static void swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
static int partition(int[] a, int start, int end) {
int value = a[end]; // 기준값
int i = start - 1; // i는 1구역의 끝지점
for (int j = start; j <= end - 1; ++j) // j는 3구역의 시작 지점
if (a[j] < value) // a[j] 값이 1구역에 속하면
swap(a, ++i, j); // a[j] 값을 1구역의 끝에 추가한다. 1구역 크기 1증가.
swap(a, i + 1, end); // 기준값인 a[end] 원소와 2구역의 시작 원소를 교환한다.
return i + 1; // 기준값 위치 리턴
}
3) 퀵 정렬 구현
static void quickSort(int[] a, int start, int end) {
if (start >= end)
return;
int middle = partition(a, start, end); // 배열 나누기
quickSort(a, start, middle-1); // 1구역 정렬
quickSort(a, middle+1, end); // 2구역 정렬
}
4) 퀵 정렬 수행 시간
partition 메서드의 수행시간은 O(n)이다.
평균
quickSort 메서드의 재귀 호출 횟수의 평균은 logn이다.
따라서 퀵정렬의 평균 수행시간은 O(nlogn)이다.
최선
partition 메서드가 배열을 정확히 1/2로 나눈다면, 재귀호출 횟수는 logn이고
따라서 퀵정렬의 최선일 때 수행시간은 O(nlogn)이다.
최악
partition 메서드가 배열을 0: n-1 크기로 나눈다면, 재귀호출 횟수는 n이다.
따라서 최악일 때, 퀵 정렬 수행시간은 O(n^2)이다.
=> 최악인 경우가 있기 때문에 기준값을 중간값으로 바꾸고 해보았지만 역시 시간 초과
2. quick select
static void swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
static int partition(int[] a, int left, int right) {
int mid = (left + right) / 2;
swap(a, mid, right);
int pivot = a[right];
int j = left - 1;
for (int i = left; i < right; i++) {
if (a[i] < pivot) {
swap(a, i, ++j);
}
}
j++;
swap(a, right, j);
return j;
}
// a 배열의 start~end 에서 nth 번째 작은 값을 리턴한다.
static int select(int[] a, int start, int end, int nth) {
if (start >= end)
return a[start]; // 찾을 배열의 크기가 1 이면 리턴
int middle = partition(a, start, end); // 배열 나누기
int middle_nth = middle - start + 1; // middle 위치의 값이 start~end 에서 middle_nth 번째 작은 값
if (nth == middle_nth)
return a[middle]; // 찾았으면 리턴
if (nth < middle_nth)
return select(a, start, middle-1, nth); // 앞 부분에서 찾는다.
else
return select(a, middle+1, end, nth - middle_nth); // 뒷 부분에서 찾는다.
}
근데 이렇게 해도 안된다. 대체 왜 (띠용)
partition 메소드에서 위 코드처럼 기준값을 중간값으로 바꿔줬는데도 시간초과가 뜬다.
3. 백준 11004번 문제
partition 메소드에 문제가 있는 것 같아서 아래의 메소드로 바꿨는데 시간초과가 뜨지 않는다.
public static int partition(int[] array, int left, int right) {
int mid = (left + right) / 2;
swap(array, left, mid); // 중앙 값을 첫 번째 요소로 이동
int pivot = array[left];
int i = left, j = right;
while (i < j) {
while (pivot < array[j]) { // j는 오른쪽에서 왼쪽으로 피봇보다 작거나 같은 값을 찾는다.
j--;
}
while (i < j && pivot >= array[i]) { // i는 왼쪽에서 오른쪽으로 피봇보다 큰 값을 찾는다.
i++;
}
swap(array, i, j); // 찾은 i와 j를 교환
}
// 반복문을 벗어난 경우는 i와 j가 만난경우
// 피봇과 교환
array[left] = array[i];
array[i] = pivot;
return i;
}
5. 간단한 데이터베이스를 만들어 놓은 상태입니다. project 스키마에 Member 테이블을 생성하였습니다.
CREATE TABLE `Member` (
`id` varchar(45) NOT NULL,
`name` varchar(45) NOT NULL,
`password` varchar(45) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
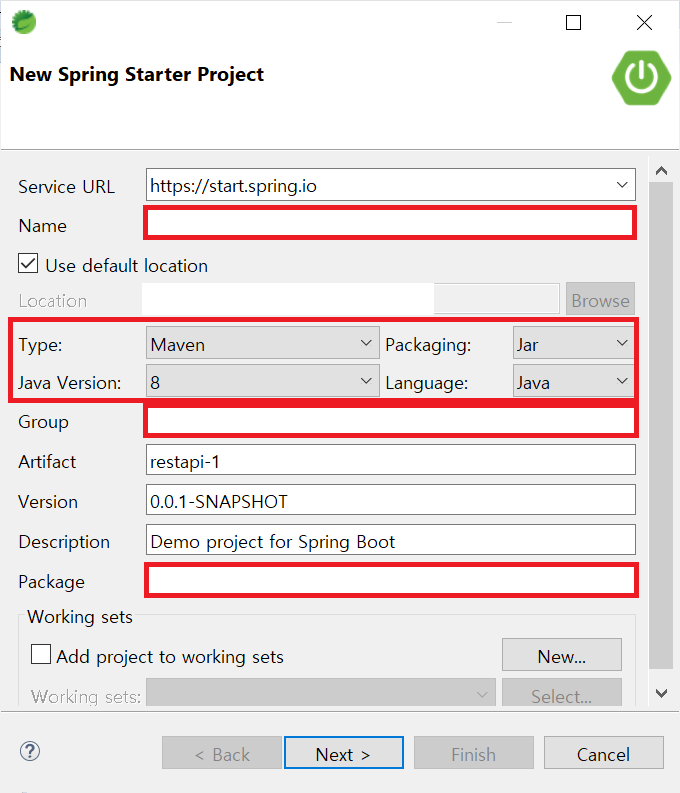
1. Spring Boot 프로젝트 생성
1) 프로젝트 생성
[File - New - Spring Starter Project]
Type : Maven / Packaging : Jar로 설정하고
Name, Group, Package 명을 입력한다.
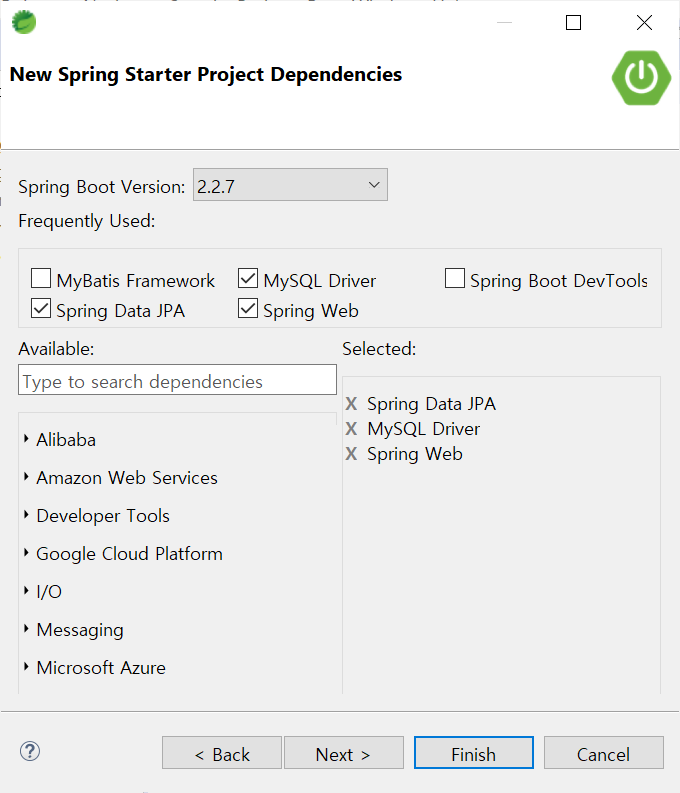
Spring Web/ MySQL Driver/ Spring Data JPA 를 선택하고 [Finish] 버튼 클릭
2) application.properties
src/main/resources/application.properties
# API 호출시, SQL 문을 콘솔에 출력한다.
spring.jpa.show-sql=true
# DDL 정의시 데이터베이스의 고유 기능을 사용합니다.
# ex) 테이블 생성, 삭제 등
spring.jpa.generate-ddl=true
# MySQL을 사용한다.
spring.jpa.database=mysql
# MySQL 설정
spring.datasource.hikari.driver-class-name=com.mysql.cj.jdbc.Driver
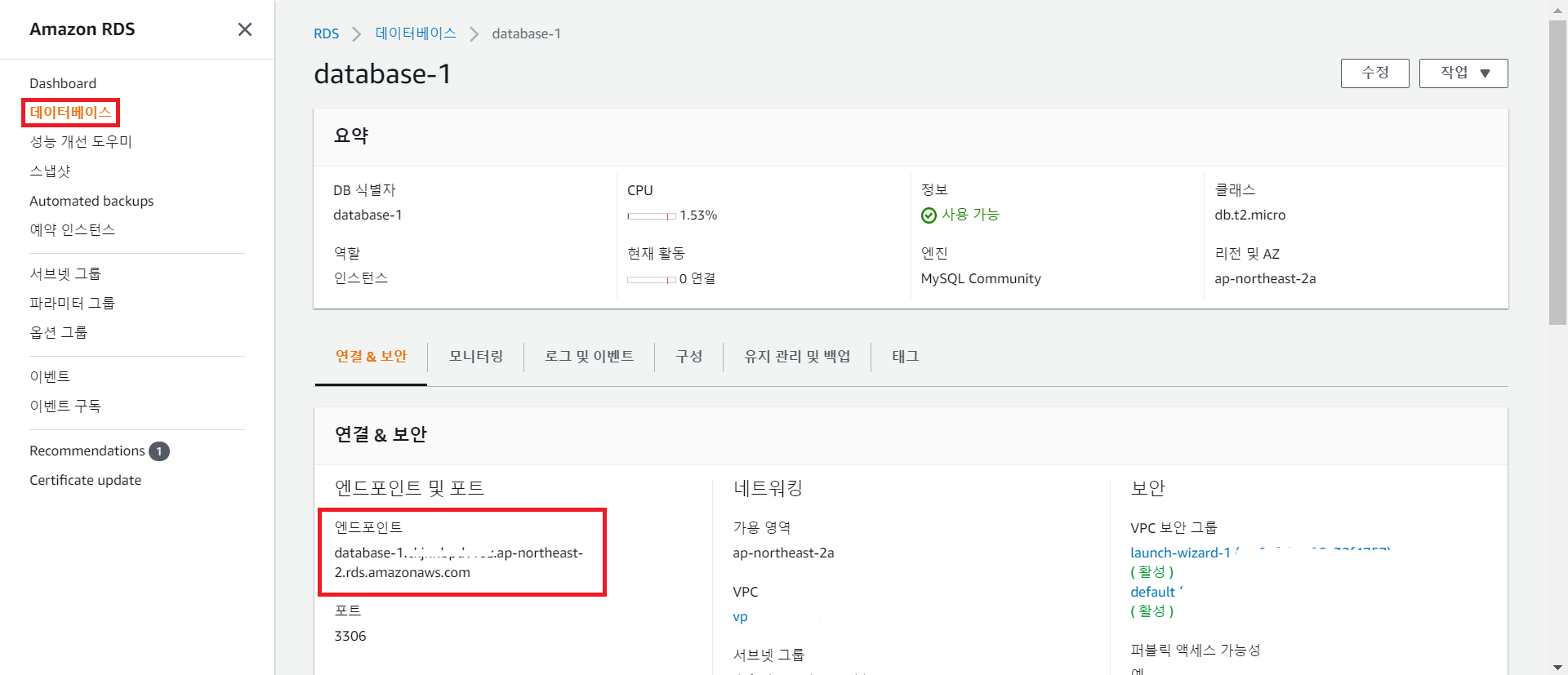
spring.datasource.hikari.jdbc-url=jdbc:mysql://database-1.(생략).ap-northeast-2.rds.amazonaws.com:3306/project?useUnicode=yes&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Seoul
spring.datasource.hikari.username=user1
spring.datasource.hikari.password=test1234
# MySQL 상세 지정
spring.jpa.hibernate.naming.physical-strategy=org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect
spring.jpa.database=mysql
spring.jpa.show-sql=true
application.properties는 spring Boot 설정 파일이다.
MySQL 설정에서 hikari를 써준 이유는 hikari Connection Pool를 사용하기 위함이다. hikariCP를 사용하지 않을 경우 그냥 spring.datasource.diver-class-name 등으로 작성하면 된다.

















댓글 개